

Cutter Consortium Senior Consultant Lynn Winterboer's webinar on Writing User Stories and Slicing Epics for DW/BI Teams concluded with a lively Q&A session. Here are Lynn's responses to four of the most frequently asked questions.
Q1: "How can a user story span all layers -- is that not an epic?"
LW: I'm going to refer to Figure 1 -- thin slicing points. This is a standard-looking data warehouse set of DW/BI layers all the way from source to BI front end.
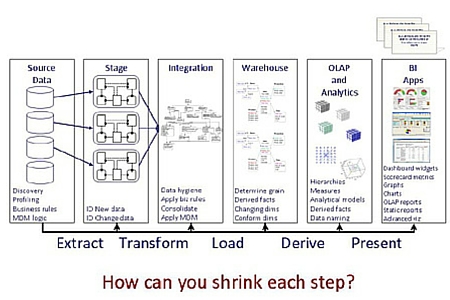
When we thin slice, there are all these different opportunities, as we go through each layer to make decisions about how deep into each of those layers we are going to slice. And we must ask ourselves, "How can we shrink each step?" One example is to do change data capture as a follow-on story, instead of in the staging layer. Another example is to do data hygiene, or to pull the data all the way through to the BI layer, without doing data cleansing. You might want to have your business look at the data before deciding whether to perform data cleansing. If when you pull the data all the way through, and your business sees that only .1% of this field has a data quality issue, they may say, "That's fine. That's within tolerable limits. You don't need to ever cleanse that data." You've just saved yourself some work and some time and you can move on to something of more value. Each example is a way you can shrink each step and come back and do it later in a different story, if that adds value.
I'll admit it can be very confusing to hear about all these layers and it can feel really overwhelming. What I can tell you is that there are a lot of teams doing very complex data warehousing work that adheres to this architecturally complete concept. And there are other teams that don't necessarily adhere to it. I would say that what works best for you, and what delivers value to the business, should be your primary focus.
I have seen a lot of teams split stories between the DW and BI layers. If they don't have some architecture going across -- some planning -- that spans both of those teams and has them coordinated, the data warehouse team ends up working in a silo. The value, from when you talk about "what the business needs" to "when you deliver value," can take a very long period of time. I've seen teams take nine weeks to three months to deliver what is, in essence, a story from the business's point of view. You lose your business's attention. They don't feel like they're getting value very quickly.
There are ways to manage this, though. If the DW and the BI teams are both working on the same concept, or they are one iteration lagging, maybe that's soon enough for your business. Maybe if you have iterations of two weeks, and you talk about it in week one as a whole concept, and if DW does its work in weeks one and two, and BI does its work in weeks three and four, and the business sees it a month later, if the business is delighted, then fine. But if you lose your business in that interim, then it's a problem. You need to think about slicing thinner across these iterations.
Q2: "In regulated industries, such as medical devices, how are the regulatory requirements taken into account? Releases are difficult to coordinate when there has to be a definitive implementation to draw a line in the sand from a documentation standpoint."
LW: That's a really good question. And a common one. In regulated industries, such as healthcare and financial services, there are a lot of questions that come up. I believe you really need to try and include that information in your definition of "done." If you can fill out your documentation a little bit at a time, it makes it not such a big task to fill it out in the end. Including your regulatory requirements in your definition of done is one way to manage it.
Another way that I've seen teams do it is to have what they call a "hardening sprint," which is useful for DW teams because DW teams might do preproduction testing, or production-level testing, or they might do load and stress testing during that time -- things that may be difficult to do every couple of weeks given your data volumes and maybe your technical infrastructure can't support testing on huge data volumes every couple of weeks, but you do have a test environment where you can load lots and lots of data and really pound it. A hardening sprint would be right before your release and during that hardening sprint is when I have seen financial institutions, in particular, take that time to really meet all regulatory requirements.
You have to step back and think creatively and look at values and principles. You have to say that your goal is to deliver value to the business and that value is defined by the business, not by IT, and you want to deliver it frequently and consistently. So if you do a release every three months, and you need to take a hardening sprint to work on meeting regulatory requirements, typically the business doesn't mind because they understand. They're part of that business and they respect that the regulatory requirements are there for a reason and you can't get out of them. So you have to do them.
Q3: "What's an example of good acceptance criteria -- outside of that the report should match the mockup/data should be accurate?"
LW: Acceptance criteria is a big topic. A simple example can be seen in Figure 2, in the most profitable transactions.

We've simplified it down to where we need to see profit per customer per transaction, so that we can identify the characteristics of the most profitable transactions. One example is when XYZ manufacturing places order number 13579 for three widgets for $100 each. This is our acceptance criteria. They've placed an order for three of our products at $100 each, and the widgets are on sale for 10% off, and the cost of goods sold for each widget is $50, then the profit for this order should be $120.
If you do the math, it works out that $300 less 10% ($30) less $150 = $120. This is what's called "behavior-driven development." This is a format. When something happens, and it has X criteria, and it also has Y criteria, then Z happens. It's a great method in the data world for the stakeholders and product owner to clarify what they mean and what they're expecting to see. In this case, you might have several different scenarios -- and this could come out of a use case scenario -- so you might have a handful of these examples. And I like it when the person requesting this, the stakeholder, comes to me and says, "OK, here are five orders that I've picked out of our system and they each meet a different criteria. This one has 10% off. This one has $5.00 off each. This one doesn't have any discounts." And you would even want one that says, "If the cost of the product, less the discount, less the cost of goods sold, is negative, we want to know that it was a negative profit." So it's good to come up with a handful of examples that flesh out what they want to see. It gives you test data to unit test on, and you can automate that. So when you have an actual order, where they say "Run this through and here's what I expect the profit number to be," then you can automate that very easily. You can say, "Here's the input of this order with these elements and here's the expected profit that's going to calculate in the end." That's a beautiful way to go.
However, it is very time-consuming. And it can feel completely overwhelming to some teams who aren't set up to do that. It's very useful to have the testers involved, or someone with testing skills involved because he or she can say, "I see your story, here. Let's pull a few orders out that meet these scenarios." The testers can get going on writing the tests and getting the test data set up and automating those tests right away before the developer even does any development. That' s a great way to do it.
Q4: "What is your recommended sprint length for a DW team given the fact that it takes longer to deliver a DW solution?"
LW: I personally think that teams should start out with shorter sprints. If you're doing an Agile transformation and you're moving toward an Agile approach, if you start out with a one-week iteration with really thin-sliced stories, you'll learn the Agile process and you'll learn what your team can and cannot handle much faster.
A key aspect of an Agile approach are the learning cycles. In a traditional data warehouse, you might have two releases a year, and you don't show anything to the customer until they are in UAT (user acceptance testing). That's two learning cycles a year. We do these things called "post-mortems" to reflect back on the project and for us to get feedback. But two learning cycles is not that many in a year. So if you're a new team starting out with Agile, and you go to one-week iterations, you have a learning cycle at the end of every iteration, at the end of every week. It's going to slow you down, but you're learning faster. And then you can expand to two- or three-week iterations. The typical sprint length or iteration length is two weeks. I have seen DW teams that try to start off with nine-week iterations, but that is not enough learning cycles and you always bite off more than you can chew in your first few iterations. We're used to doing really big work, not little teeny pieces of work. If you start out with a nine-week iteration, and you work as fast and hard as you can for nine weeks, and you're doing it in this new mindset with these new approaches, and you've got all this overhead of learning with all this process change, and you get to the end of the nine weeks and you don't hit your goal, it's really disheartening. And you can lose your business's attention. You can lose their support.
I suggest when teams start off, they go with shorter iterations, and once they feel they've got the Agile process down, and they're working together well, and they've got a good mindset shift, then they can expand to two or three weeks. Anything bigger than that and you're shortchanging yourself on your learning cycles.
Lynn welcomes your comments about this Advisor. Please send your comments and insights to her at lwinterboer@cutter.com.
